|
I am a Research Scientist at Meta Robotics Studio. Previously, I was a Robotics Research Scientist at Apple. I received my PhD from UC Berkeley, where I was advised by Ken Goldberg in the Berkeley Artificial Intelligence Research (BAIR) lab. I have also been fortunate to collaborate with researchers from Google DeepMind, NVIDIA SRL, Honda Research Institute, Siemens AI, and Uber ATG. My research primarily investigates scalable imitation learning for robot manipulation. Email / CV / Google Scholar / LinkedIn / Twitter |

|
|
The goal of my research is to build toward a future where robots are capable of human-level dexterity. I have investigated this goal mostly in the context of scaling up robot imitation learning. This includes learning dexterous manipulation from large-scale egocentric human video (EgoDex, Humanoid Policy ~ Human Policy), online imitation learning algorithms that scale to large robot fleets (Fleet-DAgger, ThriftyDAgger), synthetic data generation (IntervenGen), robot-free data collection via augmented reality (ARMADA), and community-wide efforts to train large vision-language-action models (RT-X). In addition to selected publications below (see my CV for the full list), check out:
|
|
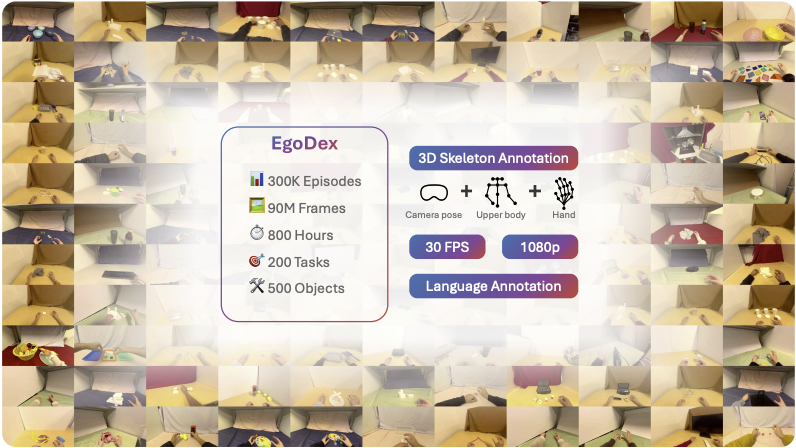
Ryan Hoque*, Peide Huang*, David J. Yoon*, Mouli Sivapurapu, Jian Zhang EgoAct Workshop at Robotics: Science and Systems (RSS) 2025. Best Paper Award. [Paper] [Website] [Twitter TL;DR] We introduce the largest and most diverse dataset of dexterous human manipulation to date: 829 hours of egocentric video and paired 3D hand poses across 194 tasks. We also train and systematically evaluate imitation learning policies for hand trajectory prediction with new metrics and benchmarks. |

|
Open X-Embodiment Collaboration (incl. myself and 172 other authors) IEEE International Conference on Robotics and Automation (ICRA) 2024. Best Conference Paper Award. [Paper] [Website] [Twitter TL;DR] (In collaboration with Google DeepMind and 33 academic labs) Cross-embodiment fleet learning with heterogeneous robots. An open-source dataset of 1M+ robot trajectories from 22 robot embodiments, and results with robot foundation models trained on this data. |

|
Ri-Zhao Qiu, Shiqi Yang, Xuxin Cheng, Chaitanya Chawla, Jialong Li, Tairan He, Ge Yan, David J. Yoon, Ryan Hoque, Lars Paulsen, Ge Yang, Jian Zhang, Sha Yi, Guanya Shi, Xiaolong Wang Conference on Robot Learning (CoRL) 2025. [Paper] [Website] [Twitter TL;DR] (In collaboration with UCSD, CMU, UW, and MIT) We co-train a human-humanoid behavior policy on large-scale egocentric human video and small-scale robot teleop data and deploy it on a humanoid robot performing manipulation tasks. |
|
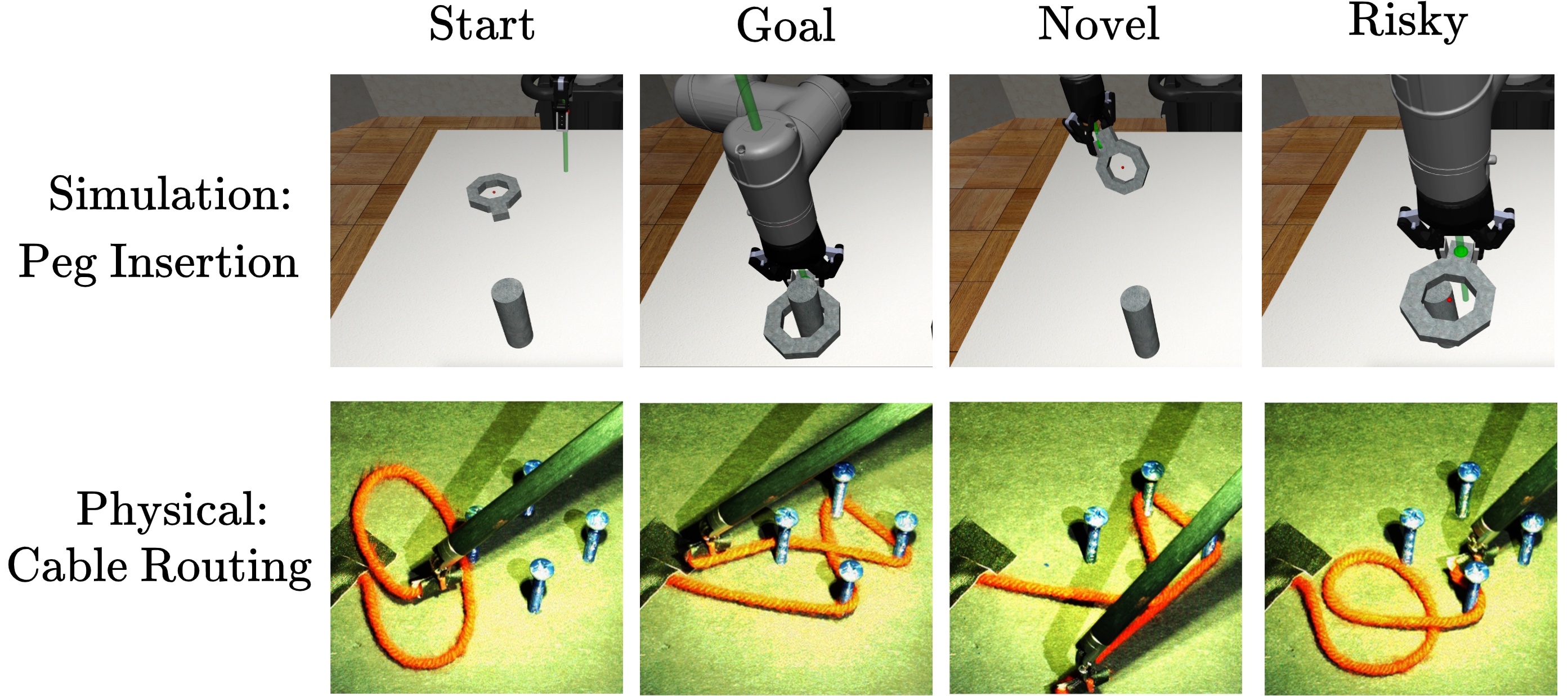
Ryan Hoque, Ashwin Balakrishna, Ellen Novoseller, Daniel S. Brown, Albert Wilcox, Ken Goldberg Conference on Robot Learning (CoRL) 2021. Oral Presentation (6.5% of papers). [Paper] [YouTube] [Website] [Twitter TL;DR] A state-of-the-art robot-gated interactive imitation learning algorithm that reasons about both state novelty and risk to actively query for human interventions more efficiently than prior algorithms. |

|
Ryan Hoque, Lawrence Yunliang Chen, Satvik Sharma, Karthik Dharmarajan, Brijen Thananjeyan, Pieter Abbeel, Ken Goldberg Conference on Robot Learning (CoRL) 2022. Oral Presentation (6.5% of papers). [Paper] [YouTube] [Website] [Twitter TL;DR] We introduce new formalism, algorithms, and open-source benchmarks for "Interactive Fleet Learning": interactive learning with multiple robots and multiple humans. |
|
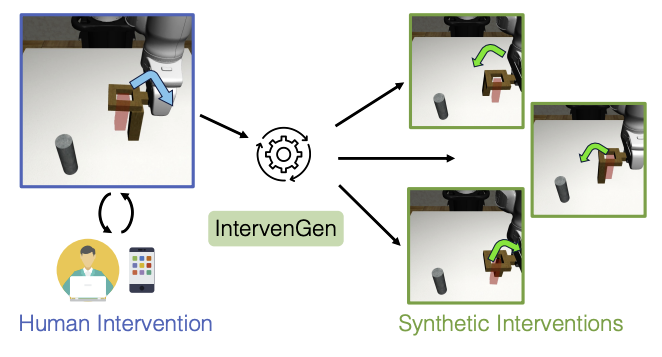
Ryan Hoque, Ajay Mandlekar, Caelan Garrett, Ken Goldberg, Dieter Fox IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2024. [Paper] [Website] [Twitter TL;DR] (In collaboration with NVIDIA SRL) A data generation system extending MimicGen to the interactive imitation learning setting, improving policy robustness up to 39x with a data budget of only 10 human interventions. |

|
Ryan Hoque*, Daniel Seita*, Ashwin Balakrishna, Aditya Ganapathi, Ajay Tanwani, Nawid Jamali, Katsu Yamane, Soshi Iba, Ken Goldberg Autonomous Robots. Vol 45(5), 2021. [Paper] [Website] (In collaboration with Honda Research Institute) A novel model-based reinforcement learning technique that trains a visual dynamics model for sequentially manipulating fabric toward a variety of goal images, entirely from random interaction RGBD data in simulation. |
|
I'm a Bay Area native and a lifelong bear: I did my undergrad, Master's, and PhD all in EECS at UC Berkeley in a single stretch of 8 years. Outside of research, I enjoy playing piano covers of heavy metal bands, reading and writing about philosophy, traveling, and exploring the outdoors. For the philosophically inclined, I am steadily working on a book on metaphysics and mysticism, but it's still in progress - stay tuned! |
|
Website template from BAIR alum Jon Barron. |